iOS 内存架构深度解析:堆 (Heap) 与 栈 (Stack)
iOS 内存架构深度解析:堆 (Heap) 与 栈 (Stack)
序言:超越“自动与手动”
在面试中,关于堆和栈的区别,初级回答通常停留在“栈自动释放,堆手动管理”。作为架构师候选人,我们需要从内存布局、指令级效率、虚拟内存映射以及多线程模型四个维度,彻底阐述这两者的本质区别。
核心痛点往往在于混淆了**“指针变量本身(存放在栈)”与“指针指向的对象实体(存放在堆)”**。
第一部分:核心概念与直观模型
1.1 酒店模型比喻
为了建立空间感,我们将内存管理比作一个酒店管理系统:
-
栈 (Stack) —— 酒店前台的“流水线”
-
特点:极快、空间极其有限、流程严格(后进先出)、自动清理。
-
场景:函数调用就像客人办理入住。CPU(前台)快速在一张临时表格(栈帧)上写下参数、局部变量。一旦手续办完(函数返回),这张纸直接进碎纸机(SP 指针回拨)。
-
存储:基本数据类型 (Int, Bool, Struct)、对象指针(房卡)。
-
-
堆 (Heap) —— 巨大的“客房区域”
-
特点:空间巨大、分配较慢(需查找空闲位)、杂乱、生命周期长。
-
场景:真正的对象实体(如 UIView)住在客房里。前台手续办完了,客房依然存在,直到明确退房(引用计数为 0),保洁阿姨(ARC/Dealloc)才会清理。
-
存储:类的实例对象、大块二进制数据、Block(通常情况)。
-
1.2 核心差异技术指标表
| 维度 | 栈 (Stack) | 堆 (Heap) |
| 分配方式 | 系统自动。移动栈指针 (SP),纳秒级操作。 | 程序员/运行时管理。查找空闲链表,涉及锁竞争,微秒/毫秒级。 |
| 内存空间 | 极小。主线程 1MB,子线程 512KB。 | 巨大。受限于物理内存和 Jetsam 阈值 (数 GB)。 |
| 地址连续性 | 严格连续。高命中率,CPU 缓存友好。 | 高度离散。容易产生内存碎片。 |
| 生长方向 | 高地址 -> 低地址 (向下)。 | 低地址 -> 高地址 (向上)。 |
| 线程安全性 | 线程独有。无需加锁,绝对安全。 | 线程共享。多线程读写需同步机制。 |
| 崩溃形式 | Stack Overflow (递归过深)。 | OOM (内存耗尽)、Bad Access (野指针)。 |
在堆和栈的对比中,**栈的崩溃形式“递归过深”**指的是 函数调用层级过多,导致栈空间被耗尽,从而发生 Stack Overflow(栈溢出) 错误。
具体解释如下:
1. 栈的用途
栈主要用来存储函数调用的上下文信息,包括:
- 局部变量
- 函数参数
- 返回地址
- 寄存器保存值
每调用一次函数,系统会在栈上分配一段空间(称为栈帧)来保存这些信息。
2. 递归的特点
递归函数会不断调用自身,每一次调用都会在栈上分配新的栈帧。
如果递归没有正确的终止条件,或者终止条件很难达到,就会导致函数调用层级非常深。
3. 递归过深的后果
栈的空间是有限的(例如主线程 1MB),当递归层数过多时,栈空间会被耗尽,无法再分配新的栈帧。
这时程序会触发 Stack Overflow 错误,通常表现为程序崩溃。
第二部分:代码层面的内存透视
理解下行代码是区分资深工程师的关键:
- (void)analyzeMemory {
// 1. 值类型
int age = 18;
// 2. 引用类型
UIView *view = [[UIView alloc] init];
}
内存动作拆解:
-
int age = 18;
-
Stack: SP 指针移动,分配 4 字节,写入值 18。
-
Heap: 无交互。
-
-
UIView *view = … (关键点)
-
Heap: alloc 在堆区寻找一块足够大的空地,实例化 UIView 对象(存放 isa, frame, layer 等数据),假设地址为 0x60000B。
-
Stack: SP 指针移动,分配 8 字节(64位指针大小),在这个栈内存里写入地址值 0x60000B。
-
本质: 栈上的指针 指向 堆上的对象。
-
-
函数结束 }
-
Stack: age 和 view (指针变量) 瞬间销毁(弹栈)。
-
Heap: ARC 捕获到栈上的 view 销毁了,导致堆上的 0x60000B 对象引用计数 -1。若为 0,则释放堆内存。
-
第三部分:内存布局与生长方向
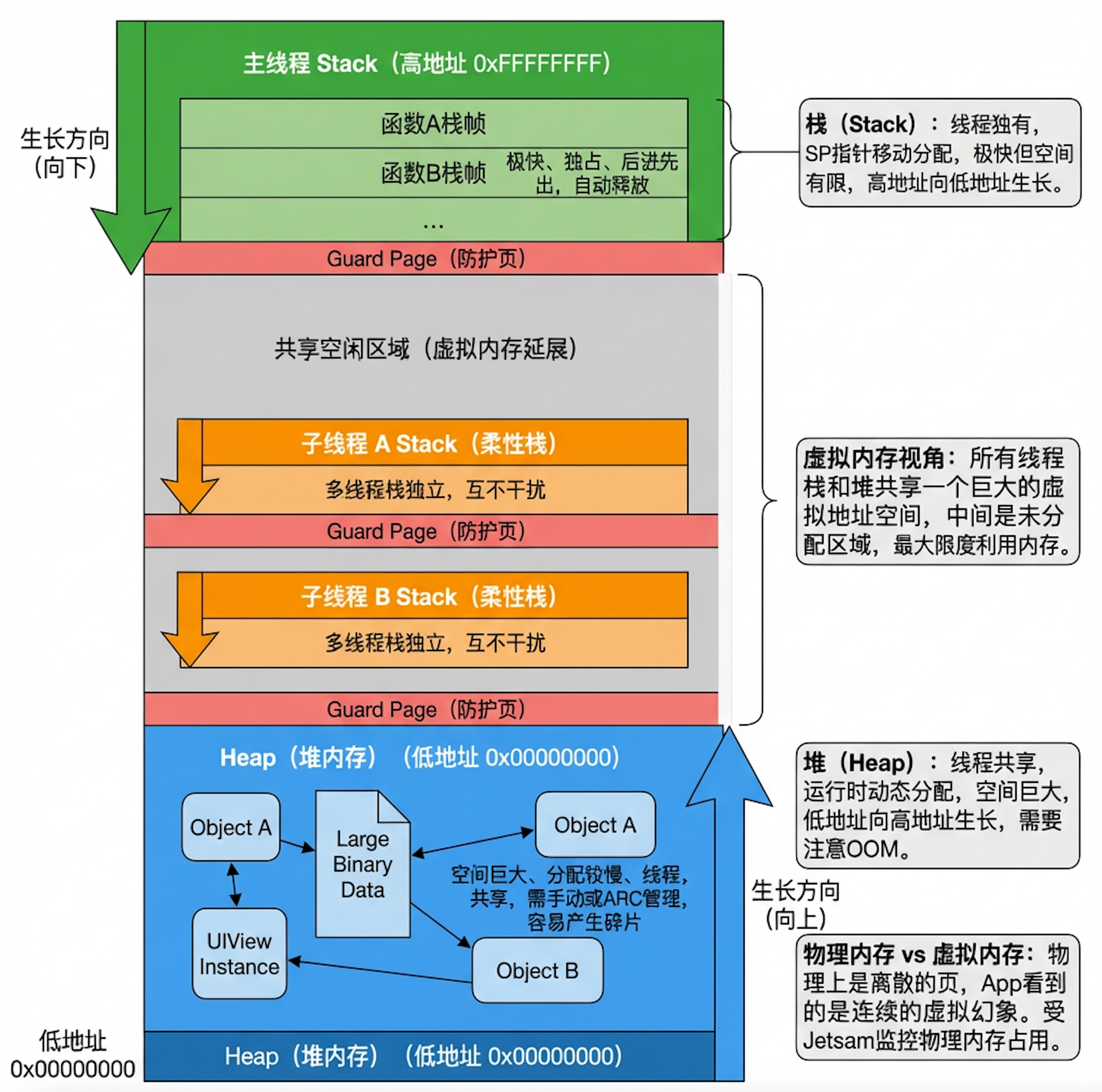
3.1 经典的内存布局图 (虚拟内存视角)
在单线程(主线程)模型下,虚拟内存呈现**“两头堵”**的态势:
[ 高地址 0xFF... ] <-- 栈底 (Stack Bottom)
|
| 栈 (Stack) 向下生长
v
(巨大的共享空闲区域)
^
| 堆 (Heap) 向上生长
|
[ 低地址 0x00... ] <-- 堆底 (代码段之上)
3.2 为什么要这样设计?
这不是物理限制,而是软件架构策略:
-
最大化利用率:栈和堆共享中间的巨大空闲区。无论是递归深(栈用得多)还是对象多(堆用得多),只要两者不相遇,就不会 OOM。
-
硬件固化:现代 CPU 指令集(如 ARM64 的 PUSH)已固化了“入栈即减小地址”的逻辑,以配合这种 ABI 标准。
第四部分:物理 vs 虚拟 —— 揭开操作系统的谎言
这是架构师必须厘清的底层真相。
4.1 物理本质
-
同源性:在物理 RAM(DRAM芯片)上,栈和堆没有任何区别,都是离散的物理页(Page,通常 16KB)。
-
无序性:栈的数据可能存在物理地址 0x1000,堆的数据可能在 0x0010。物理上完全打乱。
4.2 虚拟映射 (The Illusion)
App 看到的连续内存空间是 OS 和 MMU (内存管理单元) 编织的幻象:
-
App 启动时:OS 赋予 App 巨大的虚拟地址空间(64位下约为 TB 级别)。这只是一张“空头支票”。
-
运行时分配:App 申请 100MB 虚拟内存(圈地),物理内存占用为 0。
-
缺页中断 (Page Fault):只有当 App 真正读写这块内存时,OS 才会临时中断,从物理 RAM 中找闲置页映射过去。
4.3 持续增加机制
-
虚拟内存 (VM Size):随 alloc、加载库、开线程持续增加,几乎无上限(只要不满 64 位寻址空间)。
-
物理内存 (Resident Size):随实际使用增加。受 Jetsam 机制监控,一旦超过设备阈值(如 2GB),App 直接被 SIGKILL (OOM Crash)。
第五部分:多线程下的内存布局 (Floating Islands)
在多线程环境下,经典的“栈在顶、堆在底”模型演变为**“悬浮岛”模型**。
5.1 布局图解
主线程依然占据虚拟内存的高地,而子线程的栈则漂浮在中间的空闲区域(通常是在堆区划出的映射区域)。
[ 0xFFFFFFFF ]
| [ 主线程 Stack ] (向下)
|
| ... (空闲) ...
|
| [ Guard Page ] (保护页,防止踩踏)
| [ 子线程 A Stack ] (向下,悬浮在半空)
| [ Guard Page ]
|
| ...
| [ 子线程 B Stack ] (向下)
|
^
| [ Heap 堆内存 ]
[ 0x00000000 ]
5.2 关键特性
-
独立性:每个线程都有自己独立的栈空间,互不干扰(线程安全的基础)。
-
统一方向:无论子线程栈分配在虚拟内存的哪个地址段,其内部依然遵循 从高向低 的生长方向(受 CPU 指令决定)。
-
安全性:系统在每个栈的末端(低地址端)插入 Guard Page。一旦递归过深撞墙,硬件触发异常,抛出 Stack Overflow 错误,防止改写其他数据。
栈之所以是线程安全的,主要是因为它的内存使用方式和线程的独立性决定的。我们可以从几个关键点来理解:
5.2.1. 每个线程都有自己独立的栈空间
- 当一个线程被创建时,操作系统会为它分配一块独立的栈内存(主线程通常 1MB,子线程可能 512KB)。
- 这个栈只属于该线程,其他线程无法直接访问或修改它的内容。
- 因此,不存在多个线程同时读写同一块栈内存的情况,自然不会发生数据竞争。
5.2.2. 栈的访问是由 CPU 寄存器控制的
- 栈的读写由**栈指针(SP, Stack Pointer)**寄存器管理。
- 每个线程在 CPU 中都有自己独立的寄存器上下文,包括自己的 SP。
- 当线程切换时,操作系统会保存当前线程的 SP,并恢复另一个线程的 SP。
- 这样,线程之间的栈指针不会混用,保证了栈的独立性。
5.2.3. 栈的生命周期与线程绑定
- 栈上的数据(局部变量、函数参数、返回地址等)只在该线程的函数调用过程中存在。
- 当线程结束时,它的栈空间会被操作系统回收。
- 由于栈数据不会跨线程共享,也就不需要加锁来保护。
5.2.4. 不需要同步机制
- 堆内存是所有线程共享的,因此多线程访问同一块堆内存时需要加锁或使用其他同步机制来避免数据竞争。
- 栈内存是线程私有的,天然避免了多线程同时访问同一数据的情况,所以不需要加锁,访问速度非常快。
对比堆和栈的线程安全性
| 特性 | 栈 | 堆 |
|---|---|---|
| 所有权 | 线程私有 | 所有线程共享 |
| 访问控制 | 由线程自己的 SP 管理 | 由程序员/运行时管理 |
| 是否需要加锁 | 不需要 | 需要(多线程访问时) |
| 线程安全性 | 天然安全 | 需要额外保证 |
第六部分:架构师视角的总结
在进行系统设计或性能优化时,应遵循以下原则:
-
优先使用栈 (Struct vs Class):
- 对于高频计算、小数据结构,优先使用 Swift 的 Struct 或 C struct。这利用了栈的极致速度(无 malloc/free 开销)和线程安全性。
-
警惕栈溢出:
- 避免在栈上开辟巨型数组(如 int a[100000]),避免无限递归。
-
理解 OOM 的本质:
- OOM 崩的是物理内存(Resident Memory),不是虚拟内存。不要因为“alloc 了很多对象但没赋值”就以为内存很安全。
-
多线程成本:
- 每开一个线程,至少消耗 512KB ~ 1MB 的虚拟内存作为栈空间。虽然物理内存是懒加载的,但过多的线程管理结构依然会消耗系统资源。